บริษัทเทคโนโลยีวัดผลกระทบของ AI ต่อการพัฒนาซอฟต์แวร์อย่างไร
(newsletter.pragmaticengineer.com)- ท่ามกลางการ นำเครื่องมือ AI สำหรับเขียนโค้ดมาใช้อย่างแพร่หลาย และ ต้นทุนที่เพิ่มขึ้น บริษัทเทคโนโลยีชื่อดังต่างสรุป วิธีวัดประโยชน์ที่แท้จริงของ AI ให้เป็นตัวเลข ด้วยชุดตัวชี้วัดหลายชั้น
- แกนสำคัญคือ แนวทางแบบผสม ที่ติดตามทั้ง ตัวชี้วัดพื้นฐานด้านวิศวกรรม เดิม (เช่น PR throughput, Change Failure Rate) และ ตัวชี้วัดเฉพาะของ AI (เช่น อัตราการใช้งาน AI, เวลาที่ประหยัดได้, CSAT) ไปพร้อมกัน
- เน้น แนวคิดเชิงทดลอง ที่ใช้ การแยกวิเคราะห์ตามระดับการใช้ AI ของทีม/บุคคล/คอฮอร์ต และการเปรียบเทียบก่อน-หลัง เพื่อหาทั้ง แนวโน้มและความสัมพันธ์เชิงสหสัมพันธ์
- จำเป็นต้องมีการออกแบบอย่างสมดุลที่เฝ้าติดตาม คุณภาพ ความสามารถในการบำรุงรักษา และประสบการณ์นักพัฒนา ควบคู่ไปกับตัวชี้วัดด้านความเร็วอยู่เสมอ เพื่อป้องกัน หนี้ทางเทคนิคที่เพิ่มขึ้น และ ผลย้อนกลับจากประโยชน์ระยะสั้น
- ในระยะยาว มีสัญญาณว่าจะขยายการวัดไปถึง agent telemetry ระยะไกล และ ขอบเขตงานที่ไม่ใช่การเขียนโค้ด โดยท้ายที่สุดคำถามจะกลับไปสู่ประเด็นว่า “AI กำลังทำให้ สิ่งที่สำคัญอยู่แล้ว (คุณภาพ ความเร็วในการออกสู่ตลาด และประสบการณ์นักพัฒนา) ดีขึ้นหรือไม่”
วาทกรรมเรื่อง AI impact และช่องว่างด้านการวัดผล
- อย่างที่เห็นได้บ่อยบน LinkedIn และที่อื่นๆ มีคำกล่าวมากมายว่า AI กำลังเปลี่ยนวิธีที่องค์กรพัฒนาซอฟต์แวร์
- มีรายงานต่อเนื่องว่า โค้ดจาก AI ในสัดส่วนสูง ถูกนำไป deploy เป็น production code จริง เช่น Google 25%, Microsoft 30%
- ผู้ก่อตั้งบางรายอ้างว่า AI สามารถแทนที่วิศวกรระดับจูเนียร์ ได้ ขณะที่งานวิจัยของ METR ชี้ให้เห็นถึงความเป็นไปได้ของ การรับรู้เรื่องเวลาแบบบิดเบือนและประสิทธิภาพที่ลดลง
- สื่อมักลดทอน AI impact ให้เหลือเพียงว่า “เขียนโค้ดได้มากแค่ไหน” แต่ผลที่ตามมาคืออุตสาหกรรมกำลังเผชิญความเสี่ยงของการสะสม หนี้ทางเทคนิคครั้งใหญ่ที่สุดเป็นประวัติการณ์
- แม้จะเคยมีฉันทามติว่า LOC (จำนวนบรรทัดโค้ด) ไม่เหมาะเป็นตัวชี้วัดด้านประสิทธิภาพการทำงาน แต่เพราะ วัดได้ง่าย มันจึงกลับมาได้รับความสนใจอีกครั้ง และบดบังคุณค่าที่แท้จริงอย่าง คุณภาพ นวัตกรรม ความเร็วในการออกสู่ตลาด และความเชื่อถือได้
- ปัจจุบันผู้นำสายวิศวกรรมจำนวนมากกำลังตัดสินใจสำคัญเกี่ยวกับเครื่องมือ AI โดย ยังไม่รู้ชัดว่าอะไรได้ผลหรือไม่ได้ผล
- ตาม LeadDev’s 2025 AI Impact Report 60% ของผู้นำระบุว่า ‘การไม่มีตัวชี้วัดที่ชัดเจน’ คือความท้าทายใหญ่ที่สุด
- ผู้นำในภาคสนามรู้สึก ไม่พอใจระหว่างแรงกดดันด้านผลงานกับผู้บริหารที่ยึดติดกับ LOC และ ช่องว่างระหว่างข้อมูลที่ต้องการกับสิ่งที่วัดได้จริง ก็กำลังขยายกว้างขึ้นเรื่อยๆ
- ผู้เขียนศึกษาด้านเครื่องมือนักพัฒนามานานกว่า 10 ปี และตั้งแต่ปี 2021 เป็นต้นมาได้ทำงานให้คำปรึกษาด้าน การเพิ่มผลิตภาพและการวัด AI impact
- หลังเข้าร่วมงานในตำแหน่ง DX CTO ก็ได้ ร่วมงานกับบริษัทหลายร้อยแห่ง และเป็นผู้นำการวิเคราะห์ด้าน DevEx ประสิทธิภาพ และผลกระทบของ AI
- ในช่วงต้นปี 2025 ผู้เขียนได้ร่วมเขียน AI Measurement Framework โดยอิงจากข้อมูลของบริษัทมากกว่า 400 แห่ง
- นี่คือ ชุดตัวชี้วัดที่แนะนำสำหรับการนำ AI มาใช้และการวัดผลกระทบ ซึ่งสร้างขึ้นจากงานวิจัยภาคสนามและการวิเคราะห์ข้อมูล
- ในบทความนี้ จะพาไปดูว่า บริษัทเทคโนโลยี 18 แห่งวัด AI impact กันอย่างไรในทางปฏิบัติ และ
- ตัวอย่างตัวชี้วัดจริง จาก Google, GitHub, Microsoft ฯลฯ
- วิธีนำไปใช้เพื่อดูว่าอะไรได้ผล
- ระเบียบวิธีวัด AI impact
- นิยามและคู่มือสำหรับตัวชี้วัด AI impact
1. ตัวชี้วัดที่บริษัท 18 แห่งใช้จริง
- มีการแชร์ภาพรวมกรณีศึกษาจาก 18 บริษัท เช่น Google, GitHub, Microsoft, Dropbox, Monzo, Atlassian, Adyen, Booking.com และ Grammarly
- แม้แต่ละบริษัทจะใช้แนวทางต่างกัน แต่สิ่งที่เหมือนกันคือการโฟกัสที่ กลุ่มตัวชี้วัดหลักไม่กี่ประเภท
-
1. ตัวชี้วัดการใช้งาน (Adoption & Usage)
- DAU/WAU/MAU: แทบทุกบริษัทติดตามจำนวนผู้ใช้ที่ active รายวัน รายสัปดาห์ และรายเดือนของเครื่องมือ AI
- ความเข้มข้นของการใช้งาน/อีเวนต์การใช้งาน: Google, eBay และรายอื่นๆ แยกละเอียดไปจนถึงการเขียนโค้ด การตอบแชต และ agentic actions
- AI tool CSAT: หลายบริษัท เช่น Dropbox, Webflow, Grammarly ทำแบบสำรวจความพึงพอใจควบคู่กันไป
-
2. ตัวชี้วัดด้านผลิตภาพ (Throughput & Time Savings)
- PR throughput: หลายบริษัท เช่น GitHub, Dropbox, Webflow, CircleCI ติดตามร่วมกัน
- Time savings: วัดจำนวนเวลาที่ประหยัดได้ต่อสัปดาห์ต่อวิศวกร (Dropbox, Monzo, Toast, Xero เป็นต้น)
- PR cycle time: ใช้งานที่ Microsoft, CircleCI, Xero, Grammarly เป็นต้น
-
3. ตัวชี้วัดด้านคุณภาพ/เสถียรภาพ (Quality & Reliability)
- Change Failure Rate: เป็นตัวชี้วัดคุณภาพที่พบบ่อยที่สุดใน GitHub, Dropbox, Adyen, Booking.com, Webflow และที่อื่นๆ
- การรับรู้ด้านความสามารถในการบำรุงรักษา/คุณภาพของโค้ด: GitHub, Adyen, CircleCI ประเมินโดยเชื่อมโยงกับ DevEx
- จำนวนบั๊ก/อัตราการย้อนกลับ: Glassdoor (จำนวนบั๊ก), Toast (PR revert rate)
-
4. ตัวชี้วัดประสบการณ์นักพัฒนา (Developer Experience)
- ความพึงพอใจของนักพัฒนา/แบบสำรวจ (DevEx, DXI): ใช้ใน Atlassian, Webflow, CarGurus, Vanguard และอื่นๆ
- Bad Developer Days (BDD): Microsoft ใช้แนวคิดเฉพาะในการวัดแรงเสียดทานผ่าน ‘วันที่แย่ของนักพัฒนา’
- ภาระทางความคิดและ friction ของนักพัฒนา: Google, eBay และรายอื่นๆ
-
5. ตัวชี้วัดด้านต้นทุนและการลงทุน (Spend & ROI)
- ค่าใช้จ่าย AI (รวมและต่อ developer): บางบริษัทติดตามต้นทุนด้วย เช่น Dropbox, Grammarly, Shopify
- Capacity worked (อัตราการใช้ประโยชน์): Glassdoor วัดว่าเครื่องมือถูกใช้งานมากแค่ไหนเมื่อเทียบกับศักยภาพสูงสุด
-
6. ตัวชี้วัดด้านนวัตกรรม/การทดลอง (Innovation & Experimentation)
- Innovation ratio / velocity: GitHub, Microsoft, Webflow และรายอื่นๆ ทำให้อัตรา/ความเร็วของนวัตกรรมกลายเป็นตัวชี้วัด
- จำนวน A/B tests: Glassdoor ใช้จำนวน A/B tests ต่อเดือนเป็นตัวชี้วัดหลัก
- มีการติดตามควบคู่กันทั้ง ตัวชี้วัดผลลัพธ์ และ ตัวชี้วัดพฤติกรรมการใช้งาน เช่น เวลาที่ประหยัดได้, PR throughput, Change Failure Rate, จำนวนผู้ใช้ที่มีส่วนร่วม, อัตรานวัตกรรม
- องค์ประกอบของตัวชี้วัดแตกต่างกันไปตาม ลำดับความสำคัญของแต่ละองค์กรและบริบทของผลิตภัณฑ์ และไม่มี ตัวชี้วัดสารพัดประโยชน์เพียงตัวเดียว
2. ฐานรากที่แข็งแรง: แกนสำคัญของการวัด AI impact
- การเขียนโค้ดด้วย AI ไม่ได้เปลี่ยนเกณฑ์ของซอฟต์แวร์ที่ดี โดยคุณภาพ ความสามารถในการบำรุงรักษา และความเร็ว ยังคงเป็นหัวใจสำคัญ
- ดังนั้นตัวชี้วัดเดิมอย่าง Change Failure Rate, PR throughput, PR cycle time, ประสบการณ์นักพัฒนา (DevEx) จึงยังคงสำคัญ
- ไม่จำเป็นต้องมีตัวชี้วัดใหม่ทั้งหมด
- คำถามสำคัญคือ “AI ทำให้สิ่งที่เดิมสำคัญอยู่แล้ว ทำได้ดีขึ้นหรือไม่?”
- หากหยุดอยู่แค่ ตัวชี้วัดผิวเผิน อย่าง LOC หรืออัตราการยอมรับ ก็จะมองผลกระทบของ AI ได้ไม่ครบถ้วน
- จำเป็นต้องมีตัวชี้วัดเป้าหมายใหม่เพื่อให้เข้าใจว่าเกิดอะไรขึ้นกันแน่ในการใช้งาน AI
- สามารถดูได้ว่า AI ถูกใช้ที่ไหน ใช้มากน้อยเพียงใด และใช้อย่างไร เพื่อนำไปใช้ตัดสินใจเรื่องงบประมาณ การ rollout เครื่องมือ ความปลอดภัย และคอมพลายแอนซ์
- เมตริก AI แสดงให้เห็นสิ่งต่อไปนี้:
- มีนักพัฒนาจำนวนเท่าใด และประเภทใดบ้าง ที่นำเครื่องมือ AI มาใช้?
- AI ส่งผลต่อจำนวนงานและประเภทของงานมากน้อยเพียงใด?
- มีต้นทุนเท่าใด?
- ตัวชี้วัดวิศวกรรมหลักแสดงให้เห็นสิ่งต่อไปนี้:
- ทีมส่งมอบงานได้เร็วขึ้นหรือไม่
- คุณภาพและความน่าเชื่อถือดีขึ้นหรือแย่ลง
- ความสามารถในการบำรุงรักษาโค้ดลดลงหรือไม่
- เครื่องมือ AI กำลังลดแรงเสียดทานในเวิร์กโฟลว์ของนักพัฒนาหรือไม่
-
กรณีของ Dropbox
- ตัวชี้วัด AI
- DAU/WAU (ผู้ใช้งานแอ็กทีฟรายวัน/รายสัปดาห์)
- AI tool CSAT (ความพึงพอใจ)
- เวลาที่ประหยัดได้ต่อนักพัฒนา
- ค่าใช้จ่าย AI
- ตัวชี้วัดแกนหลัก (ใช้ Core 4 Framework)
- Change Failure Rate
- PR throughput
- ผลลัพธ์
- ผู้ใช้ AI ประจำรายสัปดาห์ = 90% ของวิศวกรทั้งหมด (สูงกว่าค่าเฉลี่ยอุตสาหกรรมที่ 50%)
- ผู้ใช้ AI ประจำมี การ merge PR เพิ่มขึ้น 20% + Change Failure Rate ลดลง
- ประเด็นสำคัญไม่ใช่แค่อัตราการนำไปใช้ แต่คือการยืนยันว่า AI มีส่วนช่วยต่อผลงานขององค์กร ทีม และบุคคลจริงหรือไม่
- ตัวชี้วัด AI
3. แจกแจงตัวชี้วัดตามระดับการใช้งาน AI
- ทำการวิเคราะห์เปรียบเทียบหลายรูปแบบเพื่อทำความเข้าใจว่า AI เปลี่ยนวิธีทำงานของนักพัฒนาอย่างไร
- เปรียบเทียบผู้ใช้ AI กับผู้ที่ไม่ใช้
- เปรียบเทียบตัวชี้วัดวิศวกรรมหลักก่อนและหลังนำเครื่องมือ AI มาใช้
- ติดตามกลุ่มผู้ใช้เดิม (cohort analysis) เพื่อสังเกตการเปลี่ยนแปลงหลังนำ AI มาใช้
- แยกข้อมูลเป็นมุมย่อย (slicing & dicing) เพื่อหาลวดลาย
- วิเคราะห์ตามคุณลักษณะ เช่น บทบาท อายุงาน ภูมิภาค และภาษาหลัก
- ตัวอย่าง: ระดับจูเนียร์มีการเขียน PR เพิ่มขึ้น ขณะที่ระดับซีเนียร์ช้าลงเพราะสัดส่วนงานรีวิวเพิ่มขึ้น
- วิธีนี้ช่วยระบุกลุ่มที่ ต้องการการฝึกอบรมหรือการสนับสนุนเพิ่มเติม และ กลุ่มที่ได้ประโยชน์จาก AI สูง
- กรณีของ Webflow
- ในกลุ่มนักพัฒนาที่มีอายุงานมากกว่า 3 ปี การใช้ AI ให้ผลด้านการประหยัดเวลาสูงที่สุด
- เมื่อใช้เครื่องมืออย่าง Cursor และ Augment Code พบว่า PR throughput เพิ่มขึ้น 20% (เปรียบเทียบผู้ใช้ AI กับผู้ไม่ใช้)
- ความจำเป็นของ baseline ที่แข็งแรง
- องค์กรที่ไม่มีพื้นฐานตัวชี้วัดด้านผลิตภาพของนักพัฒนามาก่อน จะวัดผลกระทบของ AI ได้ยาก
- สามารถสร้าง baseline พื้นฐานได้อย่างรวดเร็วด้วย Core 4 Framework (ใช้โดย Dropbox, Adyen, Booking.com เป็นต้น)
- ใช้ทั้งข้อมูลจากระบบ ข้อมูลเก็บตัวอย่างประสบการณ์ และแบบสำรวจเป็นประจำร่วมกัน เพื่อให้การเปรียบเทียบมีความน่าเชื่อถือสูง
- หัวใจสำคัญคือการติดตามอย่างต่อเนื่องและแนวคิดแบบทดลอง
- การวัดเพียงครั้งเดียวไม่มีความหมาย ต้อง ติดตามแบบอนุกรมเวลา เพื่อดูแนวโน้มและรูปแบบ
- จุดร่วมของบริษัทที่ประสบความสำเร็จคือ ตั้งเป้าหมายที่ชัดเจนและใช้ข้อมูลทดสอบสมมติฐาน
- ไม่ยึดติดกับข้อมูลแบบตาบอด แต่รักษา mindset การทดลองที่ยึดเป้าหมายเป็นศูนย์กลาง
4. ข้อควรระวังด้านความสามารถในการบำรุงรักษา คุณภาพ และประสบการณ์นักพัฒนา
- การพัฒนาที่มี AI ช่วยยังเป็นพื้นที่ใหม่
- ยังมีข้อมูลไม่เพียงพอที่จะพิสูจน์ผลกระทบระยะยาวต่อคุณภาพโค้ดและความสามารถในการบำรุงรักษา
- โจทย์สำคัญคือการหาสมดุลระหว่างความเร็วระยะสั้นกับความเสี่ยงของหนี้ทางเทคนิคในระยะยาว
- ควรติดตามตัวชี้วัดที่คานกันไปพร้อมกัน
- บริษัทส่วนใหญ่ติดตามทั้ง Change Failure Rate และ PR throughput พร้อมกัน
- หากความเร็วเพิ่มขึ้นแต่คุณภาพลดลง นี่จะเป็นสัญญาณปัญหาทันที
- ตัวชี้วัดเพิ่มเติมสำหรับเฝ้าดูคุณภาพและความสามารถในการบำรุงรักษา
- Change confidence: ระดับความมั่นใจของนักพัฒนาต่อเสถียรภาพของโค้ดเมื่อ deploy
- Code maintainability: ความง่ายในการทำความเข้าใจและแก้ไขโค้ด
- Perception of quality: การรับรู้ของนักพัฒนาต่อคุณภาพโค้ดและแนวปฏิบัติของทีม
- จำเป็นต้องผสานตัวชี้วัดจากระบบกับตัวชี้วัดแบบรายงานด้วยตนเอง
- ข้อมูลจากระบบ: PR throughput, ความถี่ในการ deploy เป็นต้น
- ข้อมูลรายงานด้วยตนเอง: ความเชื่อมั่นต่อการเปลี่ยนแปลง, ความสามารถในการบำรุงรักษา เป็นต้น → เป็นสัญญาณสำคัญในการป้องกันผลเสียระยะยาว
- แนะนำให้ทำแบบสำรวจประสบการณ์นักพัฒนา (DevEx) เป็นประจำ
- ใช้ ตัวอย่างแบบสำรวจ เพื่อติดตามความสัมพันธ์ระหว่างคุณภาพ ความสามารถในการบำรุงรักษา และการใช้ AI
- ฟีดแบ็กแบบไม่เป็นโครงสร้างก็มีประโยชน์ต่อการค้นหาปัญหาที่มีอยู่และหารือแนวทางแก้ไข
- ความหมายที่แท้จริงของประสบการณ์นักพัฒนา (DevEx)
- ไม่ใช่สวัสดิการแนว “ปิงปอง·เบียร์” แต่คือ การลดแรงเสียดทานตลอดกระบวนการพัฒนา
- มุ่งให้เกิดประสิทธิภาพตลอดทั้งกระบวนการ ตั้งแต่วางแผน→พัฒนา→ทดสอบ→deploy→ปฏิบัติการ
- เครื่องมือ AI อาจลดแรงเสียดทานในการเขียนโค้ดและการทดสอบ แต่ก็มีความเสี่ยงที่จะเพิ่มแรงเสียดทานใหม่ในงานรีวิว การรับมือเหตุขัดข้อง และการบำรุงรักษา
- อินไซต์จากภาคสนาม (CircleCI Shelly Stuart)
- ตัวชี้วัดผลลัพธ์ (PR throughput) แสดงให้เห็นว่าเกิด อะไร ขึ้น แต่ ความพึงพอใจของนักพัฒนาแสดงให้เห็น ความยั่งยืน
- การนำ AI มาใช้สามารถสร้างความไม่สะดวกในช่วงแรกได้ ดังนั้นการติดตามความพึงพอใจจึงเป็นเครื่องมือสำคัญในการแยก แรงเสียดทานระยะสั้น vs คุณค่าระยะยาว
- 75% ของบริษัทติดตาม CSAT/ความพึงพอใจของเครื่องมือ AI ควบคู่กันไป → โฟกัสที่การสร้าง วัฒนธรรมการพัฒนาที่ยั่งยืน มากกว่าความเร็ว
5. ตัวชี้วัดที่มีเอกลักษณ์และแนวโน้มที่น่าสนใจ
- Microsoft: Bad Developer Day (BDD)
- แนวคิดในการวัดแรงเสียดทานและระดับความเหนื่อยล้าจากงานประจำวันแบบเรียลไทม์
- ปัจจัยที่ทำให้วันแย่ ได้แก่ การรับมือเหตุการณ์และงานด้าน compliance, ต้นทุนจากการสลับไปมาระหว่างการประชุมกับอีเมล, และเวลาที่หมดไปกับระบบจัดการงาน
- ใช้ควบคู่กับกิจกรรม PR (ตัวชี้วัดแทนเวลาที่ใช้เขียนโค้ด) โดยแม้จะมีงานมูลค่าต่ำบางส่วน หากยังกันเวลาไว้สำหรับการเขียนโค้ดได้ในระดับหนึ่ง ก็ถือว่าเป็นวันที่ดี
- เป้าหมาย: ตรวจสอบว่าเครื่องมือ AI ช่วยลดความถี่และความรุนแรงของ BDD ได้หรือไม่
- Glassdoor: การทดลองและการวัดอัตราการใช้เครื่องมือ
- ติดตามว่า AI ช่วยเพิ่มความเร็วของนวัตกรรมและการทดลองหรือไม่ ด้วย จำนวนการทดสอบ A/B รายเดือน
- เดินกลยุทธ์ควบคู่กันไปในการปั้น power user ให้เป็นผู้นำการใช้งาน AI ภายในองค์กร
- Capacity worked (อัตราการใช้ประโยชน์): วัดการใช้งานจริงเทียบกับปริมาณการใช้งานที่เป็นไปได้ของเครื่องมือ เพื่อประเมินจุดอิ่มตัวของการนำไปใช้และการตัดสินใจย้ายงบประมาณ
- การลดลงของ Acceptance Rate
- ในอดีตเคยเป็นตัวชี้วัด AI หลัก แต่มีขอบเขตแคบเพราะมองเพียงช่วงเวลาที่มีการยอมรับข้อเสนอ
- ไม่สามารถสะท้อนความสามารถในการบำรุงรักษา, การเกิดบั๊ก, การย้อนโค้ด, หรือผลิตภาพที่นักพัฒนารับรู้ได้
- ปัจจุบันจึงไม่ค่อยถูกใช้เป็นตัวชี้วัดระดับบนสุด แต่ยังมีข้อยกเว้น:
- GitHub: ใช้เพื่อปรับปรุง Copilot และประกอบการตัดสินใจด้านผลิตภัณฑ์
- T-Mobile: ใช้ประเมินระดับที่โค้ดจาก AI ถูกนำไปใช้จริงใน production
- Atlassian: ใช้เป็นตัวชี้วัดเสริมด้านความพึงพอใจของนักพัฒนาและคุณภาพของข้อเสนอ
- การวิเคราะห์ต้นทุนและการลงทุน
- บริษัทส่วนใหญ่ไม่ได้ติดตามต้นทุนการใช้งานอย่างเข้มงวด เพื่อหลีกเลี่ยงไม่ให้นักพัฒนาลังเลในการใช้งาน
- Shopify ใช้วิธีเฉลิมฉลองนักพัฒนาที่ใช้โทเคนมากผ่าน AI Leaderboard
- ICONIQ 2025 State of AI Report: คาดว่างบประมาณด้านผลิตภาพ AI ภายในองค์กรในปี 2025 จะเพิ่มเป็นสองเท่าเมื่อเทียบกับปี 2024
- บางแห่งเปลี่ยนไปใช้แนวทาง ลดงบประมาณการจ้างงานแล้วโยกมาเพิ่มงบเครื่องมือ AI
- การขาดหายไปของ agent telemetry
- ปัจจุบันแทบยังไม่มีการวัด แต่มีโอกาสสูงที่จะถูกนำมาใช้ ภายใน 12 เดือน
- เมื่อ autonomous agent workflow แพร่หลายมากขึ้น ความจำเป็นในการวัด พฤติกรรม ความแม่นยำ และอัตราการถดถอย ก็จะเพิ่มขึ้น
- การวัดกิจกรรมที่ไม่ใช่การเขียนโค้ดยังมีไม่เพียงพอ
- ปัจจุบันยังจำกัดอยู่ที่การช่วยเขียนโค้ด ทำให้สิ่งอย่างเซสชันวางแผนบน ChatGPT หรือการจัดการ issue ใน Jira ยังไม่ถูกรวมเข้ามามากนัก
- ในปี 2026 การใช้ AI จะขยายไปสู่ ทุกขั้นตอนของ SDLC มากขึ้น และการวัดผลก็จำเป็นต้องพัฒนาตาม
- กิจกรรมที่เฉพาะเจาะจงอย่าง code review หรือการตรวจหาช่องโหว่ วัดได้ง่ายกว่า ส่วนงานเชิงนามธรรมวัดได้ยาก
- คาดว่าจะมีการ ขยายขอบเขต ของการวัดแบบรายงานด้วยตนเอง (“สัปดาห์นี้ AI ช่วยคุณประหยัดเวลาได้เท่าไร?”)
6. ควรวัดผลกระทบของ AI อย่างไร?
- AI Measurement Framework
- พัฒนาร่วมกับ Abi Noda ผู้ร่วมเขียน DevEx Framework
- จัดทำขึ้นจากข้อมูลภาคสนามของบริษัทกว่า 400 แห่ง และงานวิจัยด้านผลิตภาพนักพัฒนาตลอดกว่า 10 ปีที่ผ่านมา
- ผสานตัวชี้วัด AI เข้ากับตัวชี้วัดแกนหลัก เพื่อประเมินทั้งความเร็ว คุณภาพ ความสามารถในการบำรุงรักษา และประสบการณ์นักพัฒนา (DevEx) ไปพร้อมกัน
- ตัวชี้วัดเดี่ยว (เช่น สัดส่วนโค้ดที่สร้างโดย AI) เหมาะกับการใช้เป็น headline แต่ ไม่ใช่วิธีวัดผลลัพธ์ที่เพียงพอ
- จำเป็นต้องใช้ข้อมูลเชิงคุณภาพ + เชิงปริมาณควบคู่กัน
- ต้องเก็บทั้งตัวชี้วัดจากระบบ (เช่น PR throughput, DAU/WAU, ความถี่ในการ deploy) และตัวชี้วัดแบบรายงานด้วยตนเอง (เช่น CSAT, เวลาที่ประหยัดได้, การรับรู้ด้านความสามารถในการบำรุงรักษา) จึงจะเข้าใจภาพหลายมิติได้
- หลายบริษัทใช้ DX ในการเก็บและแสดงผลข้อมูล และสามารถสร้างระบบแบบกำหนดเองได้เช่นกัน
- วิธีเก็บข้อมูล
- ข้อมูลจากระบบ (เชิงปริมาณ): management API ของเครื่องมือ AI (การใช้งาน ค่าใช้จ่าย โทเคน อัตราการยอมรับ) + ตัวชี้วัดจาก SCM, JIRA, CI/CD, build, และการจัดการ incident
- แบบสำรวจเป็นระยะ (เชิงคุณภาพ): แบบสำรวจรายไตรมาส/รายครึ่งปี เพื่อดูแนวโน้มระยะยาวอย่าง DevEx, ความพึงพอใจ, ความเชื่อมั่นต่อการเปลี่ยนแปลง, และความสามารถในการบำรุงรักษา ซึ่งวัดจากตัวชี้วัดระบบได้ยาก
- experience sampling (เชิงคุณภาพ): แทรกคำถามสั้น ๆ ระหว่าง workflow (เช่น หลังส่ง PR ทันทีว่า “ใช้ AI หรือไม่?” “โค้ดนี้เข้าใจง่ายหรือไม่?”)
- ลำดับความสำคัญในการลงมือทำ
- แบบสำรวจเป็นระยะคือจุดเริ่มต้นที่เร็วที่สุด: สามารถได้ข้อมูลตั้งต้นภายใน 1–2 สัปดาห์
- เช่นเดียวกับที่ความแม่นยำในการติดผ้าม่านกับการยิงจรวดนั้นต่างกัน การตัดสินใจทางวิศวกรรมก็มีความหมายได้แม้จะใช้ความแม่นยำเพียงระดับที่ให้ทิศทางได้เพียงพอ
- หลังจากนั้น หากเก็บข้อมูลด้วยวิธีอื่นควบคู่กันเพื่อ cross-check ก็จะช่วยเพิ่มความน่าเชื่อถือ
- แหล่งข้อมูลเพิ่มเติม
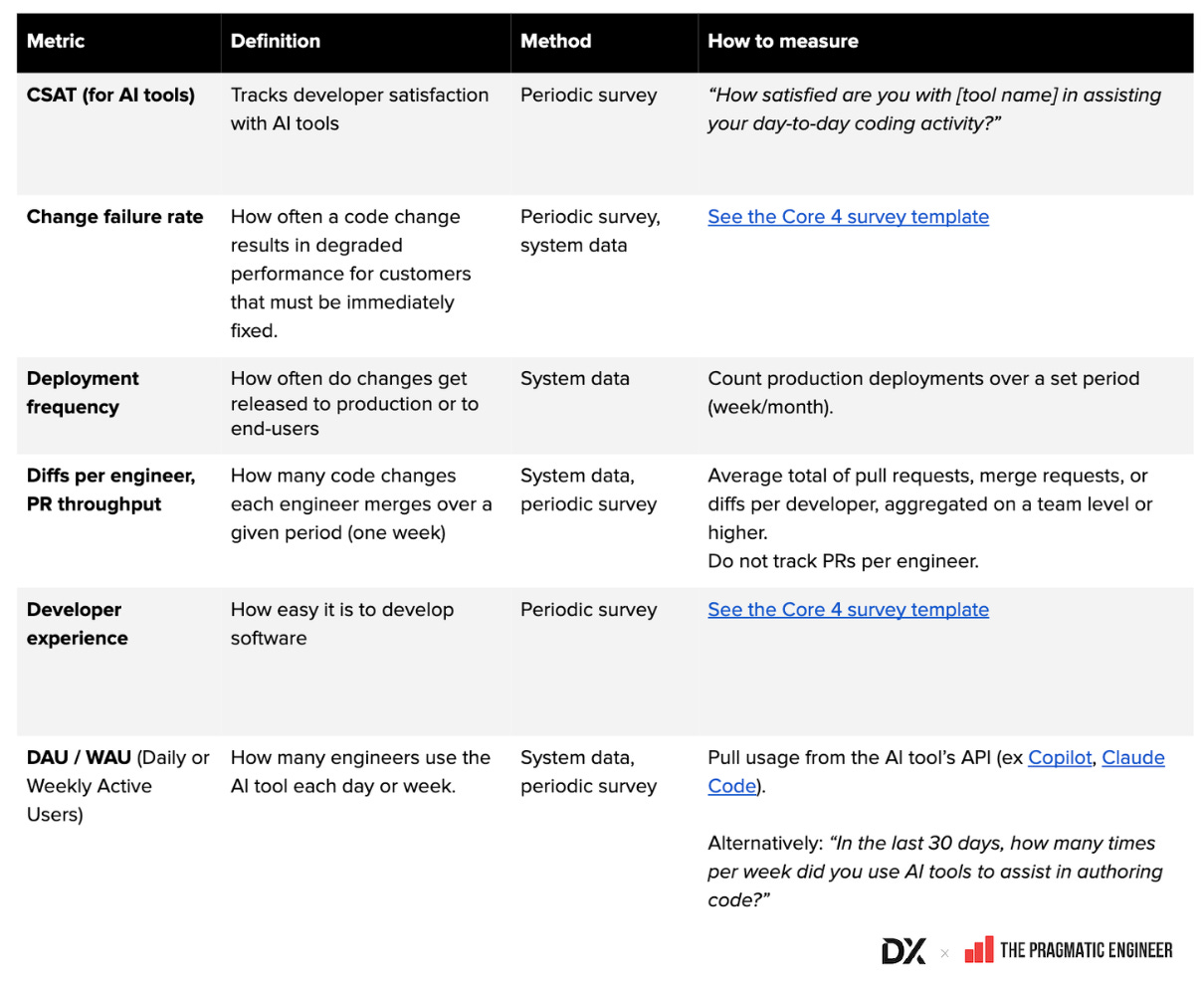
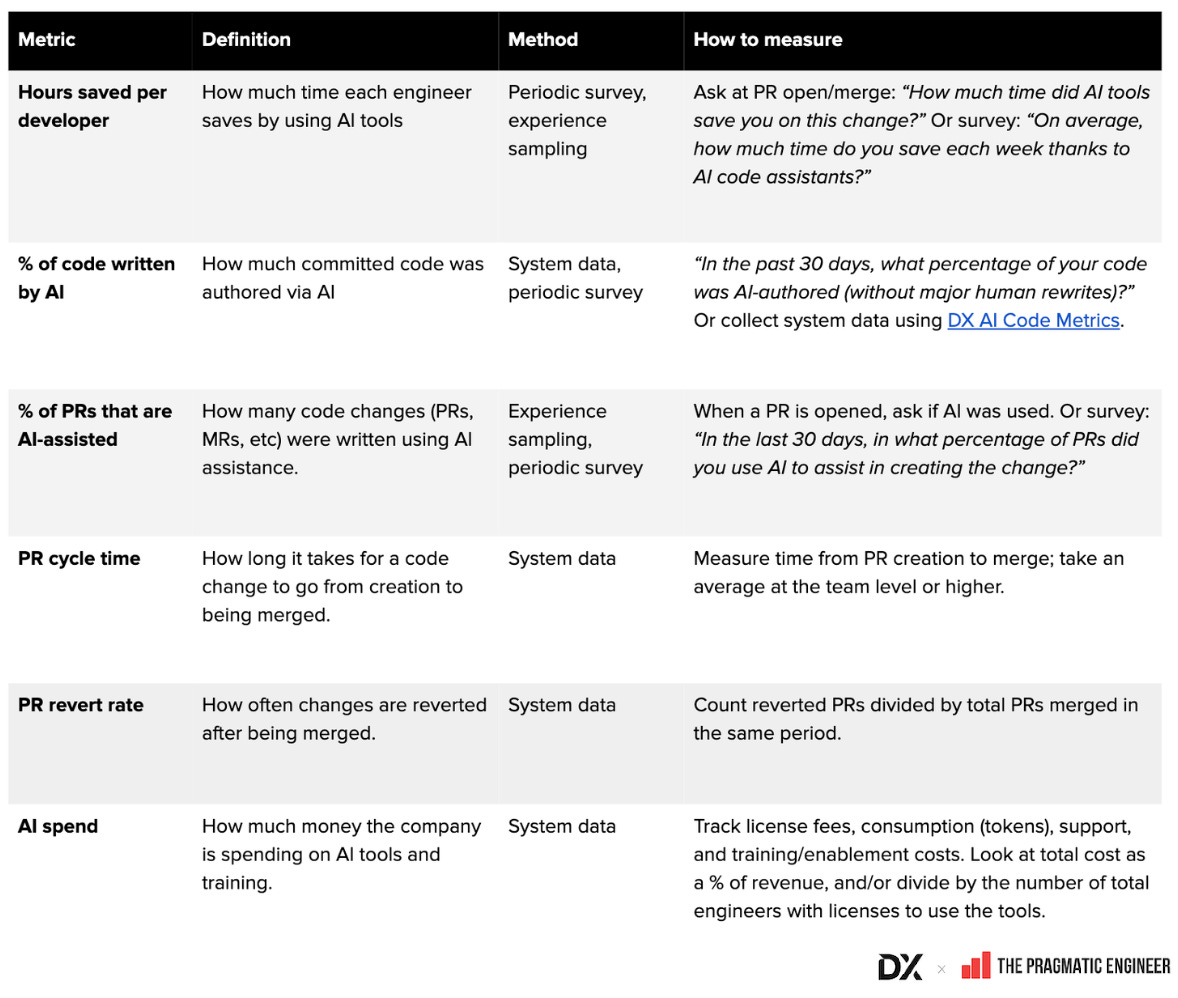
- กลอสซารีตัวชี้วัด AI ทั่วไป (Google Sheet): สรุปคำนิยาม วิธีคำนวณ และวิธีเก็บข้อมูล
- รูปตัวอย่างตัวชี้วัด AI และผลิตภาพนักพัฒนา
- ข้อพิจารณาเมื่อนำไปใช้ภายในองค์กร
- สิ่งที่ต้องตรวจสอบไม่ใช่การไล่ตามอัตราการยอมรับหรือค่าตัวชี้วัดเดี่ยว แต่คือความสามารถในการ ส่งมอบซอฟต์แวร์คุณภาพสูงให้ลูกค้าได้รวดเร็วยิ่งขึ้น ว่าดีขึ้นหรือไม่
- คำถามหลัก:
> “AI กำลังทำให้สิ่งที่สำคัญอยู่แล้ว (คุณภาพ ความเร็วในการออกสู่ตลาด และประสบการณ์นักพัฒนา) ดีขึ้นหรือไม่?” - คำถามที่ควรหยิบขึ้นมาคุยในการประชุมผู้นำ:
- นิยามผลงานทางวิศวกรรมขององค์กรเราคืออะไร?
- เรามีข้อมูลผลลัพธ์ก่อนนำเครื่องมือ AI มาใช้หรือยัง? ถ้ายัง จะตั้ง baseline อย่างรวดเร็วได้อย่างไร?
- เรากำลังสับสนระหว่าง กิจกรรม AI กับ ผลกระทบของ AI อยู่หรือไม่?
- เรากำลังรักษาสมดุลระหว่างความเร็ว คุณภาพ และความสามารถในการบำรุงรักษาอยู่หรือไม่?
- มองเห็นผลกระทบต่อประสบการณ์นักพัฒนาหรือไม่?
- เรากำลังใช้ วิธีวัดผลหลายชั้น ที่รวมทั้งข้อมูลจากระบบและข้อมูลแบบรายงานด้วยตนเองอยู่หรือไม่?
{kind=link}
{kind=link}
7. วิธีที่ Monzo วัดผลกระทบของ AI
- ช่วงเริ่มต้นการนำมาใช้
- เครื่องมือแรกคือ GitHub Copilot ซึ่งรวมอยู่ในไลเซนส์ GitHub และผสานเข้ากับ VS Code ได้อย่างเป็นธรรมชาติ ทำให้วิศวกรทุกคนเริ่มใช้งานได้ทันที
- หลังจากนั้นได้ทดสอบใช้หลายเครื่องมือควบคู่กัน เช่น Cursor, Windsurf, Claude Code โดยยังคงลงทุนต่อเนื่องโดยมี Copilot เป็นศูนย์กลาง
- ปรัชญาในการประเมินเครื่องมือ AI
- ในระบบนิเวศของเครื่องมือที่เปลี่ยนแปลงอย่างรวดเร็ว การมี ประสบการณ์ตรง เป็นสิ่งจำเป็น
- ต้องให้สมาชิกทีมใช้ AI กับโค้ดจริงทุกวัน และถึงขั้นสร้างไฟล์ตั้งค่าเอเจนต์มาใช้เอง จึงจะรู้ประสิทธิภาพได้
- การประเมินใช้ทั้ง ตัวชี้วัดเชิงวัตถุวิสัย (การใช้งาน, ประสิทธิภาพ) และ แบบสำรวจเชิงอัตวิสัย (ความพึงพอใจด้าน DX) ควบคู่กัน
- ผลลัพธ์และคุณค่าที่รับรู้ได้
- วิศวกรรู้สึกว่า AI ช่วยให้ ค้นหาเอกสาร สรุปข้อมูล และทำความเข้าใจโค้ด ได้ง่ายขึ้น และ ลดภาระทางความคิด
- ใน ตลาดแรงงานที่แข่งขันสูง หากไม่จัดหาเครื่องมือที่ดีที่สุดให้ ก็เสี่ยงที่นักพัฒนาจะย้ายออกไป → การจัดหาเครื่องมือจึงเป็นกลยุทธ์รักษาบุคลากรด้วยตัวมันเอง
- ความยากในการวัดผล
- ตัวเลขที่ผู้ให้บริการนำเสนอเป็นเพียง ตัวชี้วัดที่จำกัด เช่น อัตราการยอมรับการใช้งาน ทำให้ยากจะมองเห็นผลกระทบทางธุรกิจที่แท้จริง
- การตรวจสอบอย่างแม่นยำด้วย A/B test ก็แทบเป็นไปไม่ได้ในทางปฏิบัติ
- ยากที่จะรวบรวมข้อมูลการใช้งานจากหลายเครื่องมือ (GitHub, Gemini, Slack, Notion เป็นต้น) เข้าด้วยกัน → ข้อจำกัดด้าน telemetry และ vendor lock-in เป็นอุปสรรคหลัก
- ผลลัพธ์คือ ณ ตอนนี้ ความรู้สึกที่นักพัฒนารับรู้ได้ ยังเป็นสัญญาณหลัก
- ด้านที่ทำงานได้ดี
- ได้ผลมากใน การย้ายระบบ (migration): รับรู้ได้ว่าช่วยลดงานเปลี่ยนโค้ดลงได้ 40~60%
- ในงานที่ซ้ำๆ และทำด้วยมือ เช่น การใส่คอมเมนต์ให้ data model, LLM สามารถ ร่างฉบับแรก ให้ก่อน แล้ววิศวกรค่อยแก้ไข → ลดแรงงานได้มากในสเกลใหญ่
- บทเรียนที่คาดไม่ถึง
- ขาดความตระหนักเรื่องต้นทุน LLM: หากได้เห็นใบแจ้งหนี้จากการใช้โทเคนจริง ก็จะยิ่งรู้สึกถึงความจำเป็นในการปรับให้เหมาะสม
- ตัวอย่าง: ระบบรีวิวโค้ดอัตโนมัติของ Copilot ใช้โทเคนมากแต่ให้ผลลัพธ์น้อย จึงปิดเป็นค่าเริ่มต้นและเปลี่ยนเป็นแบบ opt-in เมื่อจำเป็น
- ด้านที่ไม่ใช้ AI
- ข้อมูลลูกค้า: ห้ามใช้ AI กับทั้งข้อมูลต้นฉบับและข้อมูลที่ลบตัวระบุแล้ว
- ให้ความสำคัญสูงสุดกับการป้องกัน ความเสี่ยงข้อมูลรั่วไหล ในพื้นที่ข้อมูลอ่อนไหว
- ปรัชญาของทีมแพลตฟอร์ม
- จัดเตรียม Guardrails: สร้างสภาพแวดล้อมการใช้งานที่ปลอดภัย เช่น การคุ้มครองข้อมูล
- แบ่งปันกรณีศึกษา: เปิดเผยอย่างโปร่งใสทั้งกรณีสำเร็จ/ล้มเหลว และประสบการณ์การใช้พรอมป์ต์
- เน้นความเป็นดาบสองคม: แบ่งปันทั้งด้านบวกและด้านลบเพื่อรักษามุมมองที่สมดุล
- ย้ำเตือนข้อจำกัดของ LLM: AI ก็มีข้อจำกัดเหมือนมนุษย์ จึงไม่ควรเชื่อมั่นเกินไป
บทสรุปและข้อสังเกต
- การวัดผลกระทบของ AI ยังเป็นพื้นที่ใหม่มาก
- ยังไม่มี “วิธีวิทยาที่ดีที่สุด” สำหรับทั้งอุตสาหกรรม
- แม้แต่บริษัทอย่าง Microsoft และ Google ที่มีขนาดและตลาดใกล้เคียงกัน ก็ยังใช้ตัวชี้วัดต่างกัน
- แต่ละองค์กรจึงมี วิธีการเฉพาะตัว และมี “flavor” ของตัวเอง
- การวัดหลายตัวชี้วัดที่อาจขัดแย้งกันพร้อมกันเป็นเรื่องปกติ
- ตัวอย่างที่พบบ่อย: ติดตามทั้ง อัตราความล้มเหลวของการเปลี่ยนแปลง (ความน่าเชื่อถือ) และ ความถี่ของ PR (ความเร็ว)
- การปล่อยใช้งานได้เร็วจะมีความหมายก็ต่อเมื่อไม่ทำลายความน่าเชื่อถือ ดังนั้นต้องวัดทั้งสองแกนอย่างสมดุล
- การวัดผลกระทบของเครื่องมือ AI เป็นโจทย์ยากคล้ายกับการวัด productivity ของนักพัฒนา
- การวัด productivity เป็นปัญหาที่อุตสาหกรรมต่อสู้กันมานานกว่า 10 ปี
- ไม่มีตัวชี้วัดเดี่ยวใดอธิบาย productivity ของทีมได้ครบถ้วน และการปรับให้เหมาะกับตัวเลขบางตัวก็ไม่ได้แปลว่า productivity จะดีขึ้นจริง
- ในปี 2023 McKinsey ประกาศว่าได้ “แก้ปัญหา” วิธีวัด productivity แล้ว แต่ Kent Beck และผู้เขียนมีท่าทีสงสัยต่อข้อสรุปนี้ → บทความโต้แย้ง
- ยังไม่มีคำตอบที่ชัดเจน แต่ก็จำเป็นต้องทดลอง
- ตราบใดที่การวัด productivity ยังไม่ถูกแก้ได้อย่างสมบูรณ์ การวัดผลกระทบของเครื่องมือ AI ก็คงยากจะคลี่คลายได้อย่างสมบูรณ์เช่นกัน
- ถึงอย่างนั้นก็ยังต้องทดลองต่อไป และพยายามหาแนวทางใหม่ๆ เพื่อตอบคำถามว่า “เครื่องมือเขียนโค้ดด้วย AI เปลี่ยนประสิทธิภาพรายวัน/รายเดือนในระดับบุคคล ทีม และบริษัทอย่างไร?”
ยังไม่มีความคิดเห็น